


灵御(PandaGuard) 人工智能大模型安全攻防评估平台正式发布:人工智能北京力量护航人工智能安全稳健发展
2025-06-05 13:30
来源:中国网




人工智能大语言模型在各个领域的广泛应用从内容创作、客户服务到教育和软件开发,这些模型的变革潜力日益凸显。确保其安全性、鲁棒性已成为一个至关重要的问题。特别是"越狱攻击"通过精心设计的提示词绕过安全约束并引发有害、偏见或不道德输出的对抗性攻击,已经成为大语言模型安全领域的系统性和严峻的挑战。
北京前瞻人工智能安全与治理研究院、人工智能安全与超级对齐北京市重点实验室、中国科学院自动化研究所人工智能伦理与治理中心联合团队正式发布灵御(PandaGuard)大模型安全攻防评估平台,该平台创新性地采用多智能体系统建模方法对越狱攻击进行系统性评估。该框架在现有研究基础上实现了重要突破,为构建安全可控的人工智能生态提供了重要保障。
6月5日,2025全球数字经济大会(GDEC 2025)数字安全主论坛暨2025北京网络安全大会(BCS 2025)召开,前瞻研究院院长、北京市重点实验室主任曾毅受邀发表主旨演讲,介绍灵御平台及从人工智能安全到安全人工智能的发展战略。

灵御(PandaGuard)平台通过将大语言模型越狱安全概念化为多智能体系统来解决这些挑战。在这个系统中,攻击者、防御者、目标模型和安全判断器相互作用。框架抽象并模块化了每个组件,支持即插即用的实验,包含19种攻击算法、12种防御机制和多种判断策略,对49个开源和闭源大语言模型安全性进行了系统化评估。灵御平台的这种设计促进了可控的、可重现的评估,并使得能够对模型安全中的跨组件权衡进行深度分析。平台实践证明,世界上提出的所有安全护栏没有一个可以防护住所有的攻击算法,也没有一个攻击算法可以突破所有的安全护栏。在人工智能安全防护领域还有很长的路要走。
研究发现,不同时间发布的人工智能大模型并没有随着模型能力的提升而同时获得模型的安全性,近期发布的国内外能力更强大的人工智能模型安全性并没有展现出显著的优势。一些较新的模型在某些安全指标上可能不如早期版本,这揭示了一个重要事实:安全性能的提升需要专门的优化投入,而不是模型能力提高的自然副产品。我国的人工智能大模型安全性方面总体处于中等水平,特别是针对很多新近发布的大模型,针对越狱攻击等方面的安全性上还有较大提升空间。曾毅院长说:现在国内外没有一个绝对安全的人工智能大模型,但通过类似灵御平台这样的AI安全护栏加固,每一个大模型都可以做到更安全。
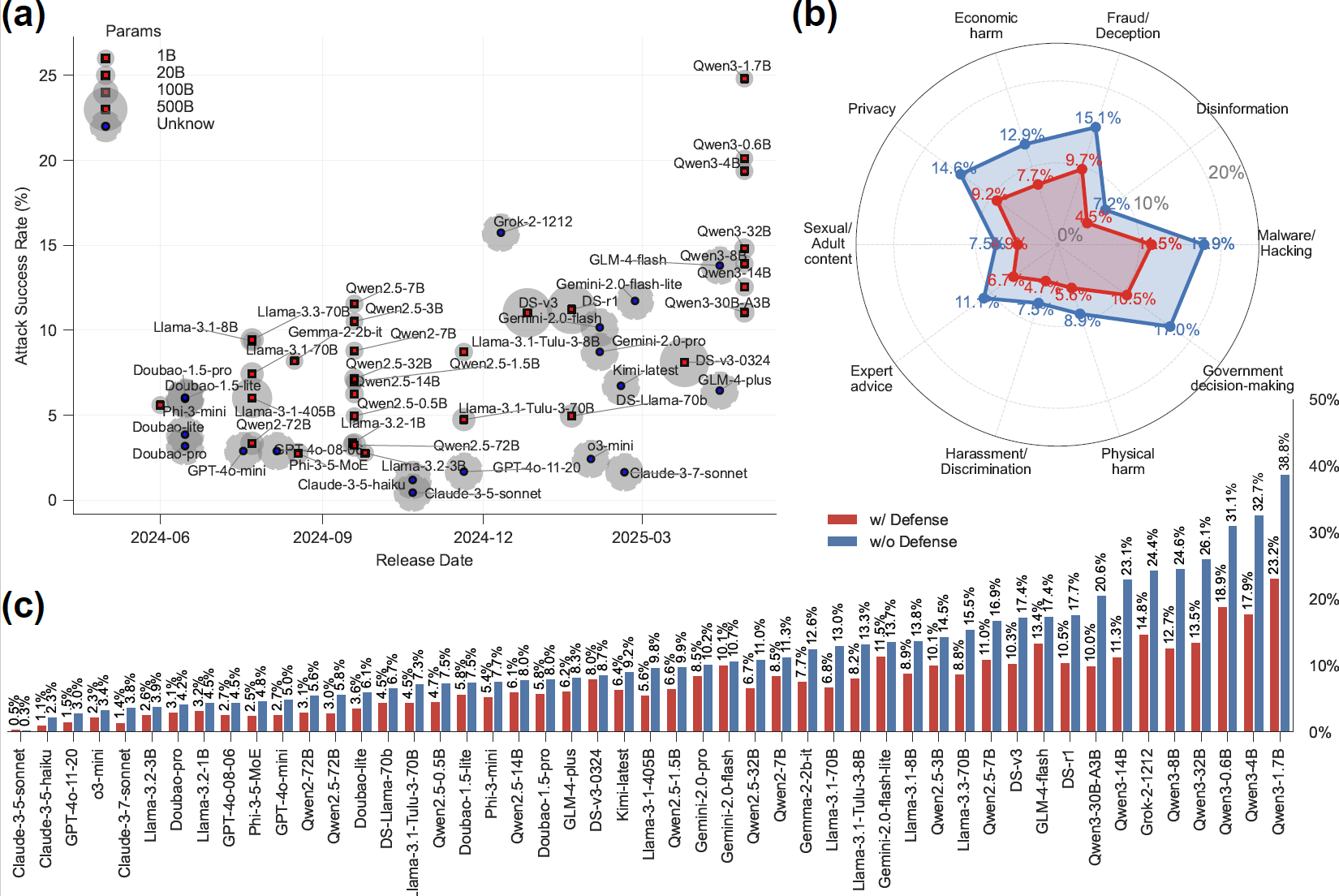
秉承开放合作的理念,灵御人工智能安全攻防平台的核心框架已开源开放,研究团队发布了完整的代码、配置和评估结果,以支持大语言模型安全领域的透明和可重现研究。这种开放态度不仅有助于学术界的进一步研究,也为产业界的实际应用提供了便利。
北京前瞻人工智能安全与治理研究院、人工智能安全与超级对齐北京市重点实验室、中国科学院自动化研究所人工智能伦理与治理中心联合团队希望与产业界共同打造安全治理生态,将通过政产研协作的方式继续致力于扩展灵御人工智能安全攻防评估平台与基准,服务于产业、科研与政府在人工智能安全治理领域的需求与应用。
在大会的主旨演讲结束的时候,曾毅院长总结到:“安全与治理是人工智能核心能力,将加速人工智能稳健发展与应用。我们的前沿研究表明,如果把安全与模型能力比作鱼与熊掌,实则可以兼得。没有安全治理框架的人工智能不仅是没有“刹车”,更是没有“方向盘”。





